摘要
近三年来,COVID-19给世界各地数百万人带来了痛苦。许多国家正在进行疫苗接种。由于问题的社会复杂性,决策的未来并不明朗。因此,需要建立数学模型来预测COVID-19动态的长期行为,以便根据疫情对经济、卫生等方面的影响做出决策。本文研究了COVID-19的短期和长期行为。采用随机进化(三分和二分马尔可夫噪声)的新方法,对不同国家不同阶段大流行的长期行为进行建模和分析。在给定条件下,随机演化模型可以帮助我们建立大流行的长期渐近行为。这使我们能够考虑大流行的不同阶段以及疫苗接种和采取的其他措施的效果。该模型的简单性使其成为根据大流行的长期行为进行决策的实用工具。因此,我们为不同地区和国家在不同阶段的比较建立了一个标准。在这方面,我们使用了来自不同国家的真实大流行数据来验证我们的结果。
1 介绍
COVID-19大流行是由2019年开始的严重急性呼吸综合征冠状病毒(SARS-CoV-2) (Mariam 2022)引起的,因此得名。冠状病毒因电子显微镜下病毒周围的光环而得名。这个光晕或冕是从病毒包膜伸出的刺突蛋白。这些病毒是单链正义RNA,大约有26到32千碱基,使它们成为最大的RNA病毒之一。最早的疑似冠状病毒感染报告之一是20世纪20年代美国北达科他州的鸡,其特征是呼吸窘迫,死亡率为40-90%。随着病毒学的发展,包括电子显微镜、组织培养和病毒的免疫学和化学特性,冠状病毒被确定为牛和猪腹泻的病因,以及小鼠肝炎和脑炎的病因,这预示着对人类的多器官影响。直到20世纪60年代,人类冠状病毒才被发现。它作为普通感冒的一种病原体被分离出来,培养然后接种到产生普通感冒的志愿者身上。乙醚灭活了病毒表明有脂质囊人冠状病毒培养困难,需要人胚胎气管器官培养作为底物。冠状病毒分为四种一般的α、β、δ和γ冠状病毒。SARS-CoV 2003、MERS - 2012和SARS-CoV-2 2019,通常被称为COVID-19,是β冠状病毒,已知会影响人类上述动物的所有器官系统。但呼吸系统通常是COVID-19在人类中的致命目标。
截至2022年5月21日,全球至少有628万人死亡,还有更多的幸存者遭受长期影响。鉴于COVID-19疾病临床过程中的这些随机变化,加上数据中存在大量背景噪声,需要一种能够从无关的白噪声中收集COVID-19大流行信号的随机模型。为了更好地阐明这一复杂过程的微妙影响,我们建议使用使用二分类马尔可夫噪声模型的数学模型来阐明疾病传播的时间过程和规模。新感染率正在增加,或者以随机(随机)方式下降,因此使用二分马尔可夫噪声模型。为了捕捉生长和衰减之间的暂停期,我们还提出使用三分马尔可夫噪声(TMN)。DMN和TMN都将在后面的部分中描述。准确的大流行预测模型有助于实施有效的大流行管理政策。SARS-CoV-2不断变异成新的变体。自然选择用传染性较强的病毒变体取代传染性较弱的病毒。最终,病毒将绕过现有的疫苗。将需要继续进行疫苗接种、新的治疗方法和更新的疫苗。这一过程可以借助于良好的数学模型。可以确定不同干预措施的相对效益,从而实现对大流行病的最有效管理。
随机进化,它被描述为一个随机变量在随机时间内取有限状态值所描述的随机过程。自然界中的许多现象都是噪声驱动的现象,即它们具有固有的随机性,是系统时空不确定性的结果,也可以解释为缺乏知识。随机进化起源可以追溯到Goldstein (Goldstein 1951;Hersh 2003)和Kac (Kac 1974)。二维随机进化称为电报过程或二分马尔可夫噪声,三态情况称为三分马尔可夫噪声或三态随机进化。有大量关于数学基础的文献(Bena 2006;平斯基1991;Pinsky and Karlin 2010;Kolesnik et al. 2011;Pinsky 1975)以及随机进化在科学、工程、生物和环境现象中的应用(Bicout 1997;Menon and yarahmaddian 2008;Harandi et al. 2014;Menon and Yarahmadian 2019, 2018)。为了对随机进化进行广泛的研究,我们建议读者参考Pinsky(1991)、Pinsky and Karlin(2010)和Ridolfi et al.(2011)的著作及其参考文献。
从数学建模的角度来看,主要关注的是人感染,这相当于世卫组织第3至6级。从预测的角度来看,还有其他因素应该包括在这些阶段中。需要考虑隔离、疫苗接种、新药、重新开放、病毒变异、感染后的自然免疫等因素。在此期间,SARS-CoV-2 2019已经演变成许多变体,但这些新变体中只有少数引起了典型的指数上升和下降的新病例浪潮。Delta型和后来的Omnicorn型变种导致了最明显的病例增加。病毒会继续变异。在未来的浪潮中,传染性的增加和致死率的降低将被选择,尽管更致命的突变可能会发生,但最终会自行消失。COVID-19的一种变体感染后,一些保护作用会传递给其他变体,但突变可能会让免疫反应逃脱。接种疫苗可在感染后提供附加保护。任何来源的免疫力都会随着时间的推移而减弱,从而导致再次感染(Baraniuk, 2007)。随着活跃感染者人数的增加和减少,COVID-19的浪潮已经发生。这些波浪对应于暴露的增加,特别是在假日聚会时。随着封锁措施的重新实施,疫情逐渐消退。突变变体在这些波浪的背后传播并获得局部优势。德尔塔变种似乎更致命,而较新的欧米克隆变种更容易传播,但不那么严重。病毒变异很快。对COVID-19自发突变率的实验室实验估计,每感染一个细胞约发生0.1个突变,而这次大流行已经感染了数万亿细胞。所以新版本的COVID-19一直在发生,偶尔一个版本比旧版本更糟糕(Shannon 1949)。引起剧烈波动的一些显著变异是印度和奥米科恩的双突变B.1.617。每一波都有早期的指数增长,然后是峰值,偶尔会有平稳期,然后下降。经过一段可变时间的低谷后,随着人与人之间互动的增加,新变体的新浪潮经常开始。
2 主要目标
当前工作的目标是提供一个及时分析大流行的有效标准,即提供一个标准来相互比较大流行的不同阶段以及不同区域/国家。在这方面,作为一种新的方法,随机进化(二分和三分马尔可夫噪声)模型被用来建立这一准则。通过这些方法,我们可以分析COVID-19疫情在世界各地的渐近行为。我们还进行了短期时间序列分析,以对大流行的每个阶段进行完整分析(Menon等人,2018),短期时间序列分析虽然本身没有增加新颖性,但我们使用现有文献并复制它,以便能够将其与长期分析进行比较。
本文的结构如下。在第1节介绍之后,随机进化技术将在第3.1节和第3.2节中讨论。第4节介绍了流行病模型方法。长期和短期分析在第5节中完成。
3.随机进化模型
随机演化是基于速度跳跃的时间演化的随机过程,即速度在有限值之间随机跳跃。因此,随机进化不同于扩散过程,扩散过程具有连续的变化率(Pinsky 1991;Pinsky and Karlin 2010。多维随机进化是由超抛物算子通过电报过程驱动的(Kolesnik et al. 2011)。这两种状态的随机演化被称为二分类马尔可夫噪声或电报过程。由于其简单直观的表示,它们已被用于建模许多具有时间随机性质的现象(Harandi et al. 2014;Ridolfi et al. 2011)。
3.1 二分类马尔科夫噪声(DMN)
二分类马尔可夫噪声,又称电报过程,是一种两态随机演化模型。它是基于连续时间两态马尔可夫链的随机过程X(t),取速率值,其中和为正常数。因此,X(t)的变化率,即,在这些常数速率之间随机转换。有两个转换频率与过程相关,描述从生长(g)到收缩(s)的转换,反之亦然。v(t)的开关由泊松过程描述(Ridolfi et al. 2011;希伯来文名字2006;yarahmaddian et al. 2015)。
通过赋值相应的概率和,分别表示系统处于生长和衰退状态,用Bicout(1997)表示系统的特征:
(3.1)该系统有如下解满足初始条件和。
(3.2)v(t)的期望值计算为:
(3.3)长期行为定义如下。
(3.4)系统的平衡状态用V表示,它将感染人群分为三种不同的状态。图1显示,当,增加的事件更频繁,感染人群总体上处于增加的类别,而减少的事件更频繁,感染人群总体上处于减少的类别。平衡状态被解释为增加和减少事件的产生之间的平衡,这产生了受感染群体的稳态平均值。
增大或缩小阶段的概率密度函数服从Fokker-Planck方程:
(3.5) (3.6)总体概率密度函数接近指数分布,平均情况为
(3.7)时,表示平均增长速度,且情况无界增长,无平稳分布值。概率密度近似于高斯分布(Ridolfi et al. 2011):
(3.8)扩散常数D为:
(3.9)3.2 三分马尔科夫噪声(TMN)
DMN可以推广为三态随机演化模型,或三分马尔可夫噪声。在这种情况下,随机过程是一个三态随机过程X(t),其中取值。与(3.1)类似,概率和开关频率可以定义如下(Menon et al. 2018)。
(3.10)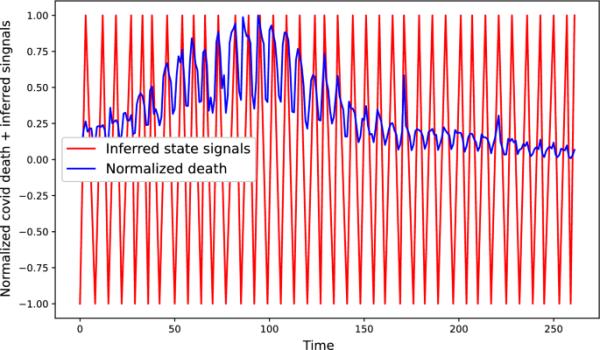
DMN和TMN事件的示例
话3.1
DMN和TMN是随机进化模型的特例。读者可以在(Menon et al. 2018)中找到必要的数学细节。
目录
摘要1 介绍
2 主要目标
3.随机进化模型
4 模型的假设
5 长期数据分析结果
6 讨论与结果
7 总结
参考文献
致谢
作者信息
道德声明
搜索
导航
#####
4 模型的假设
流行病的基本特征是易感人群、受感染人群和康复人群。根据建模中涉及的条件和假设,可以对总体进行更详细的阐述。我们建议读者参考Allen et al.(2008),对这种流行病进行了全面的数学研究。在提出的模型中,我们考虑了以下假设。正如在引言中所讨论的,由于所涉及的参数的复杂性,很难考虑一个简单的SIR模型(或一个扩展的SIR模型)进行研究。我们在这里的方法是将现象的随机性质视为在两种或三种状态下切换的随机进化模型。在这方面,我们将长期研究的重点放在该区域的死亡病例数量上。造成这种情况的主要原因是,感染病例的数量取决于报告的病例和(或)检测中的错误,而死亡病例的数量则根据报告更为确定。并假设在疫情的每个阶段,死亡病例的随机变化遵循二分类马尔可夫噪声,即随随机时间的切换,增加和减少的速率是固定的。这一假设可以通过观察以下事实得到证明:在流行病的每个阶段和每个地区,死亡病例增加和减少的原因取决于遵守预防规则的社会能力、医疗支助和死亡的受感染人口比率,这些因素在流行病的每个阶段都是固定的。也有可能观察到一段时间的停顿,这可以建模为三分马尔可夫噪声(图2)。
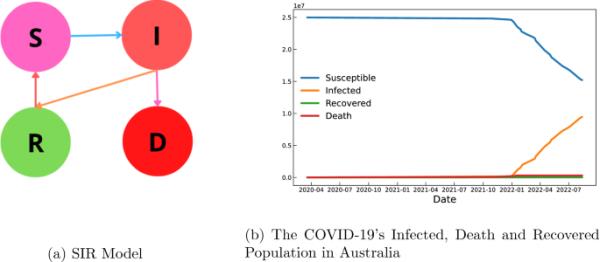
SIRD模型及基于澳大利亚数据的COVID-19 SIRD建模实例
5 长期数据分析结果
5.1 DMN参数的辨识
为了确定DMN和TMN的四个参数,即平均生长、平均衰变、从生长状态切换到衰变状态的次数和从衰变状态切换到生长状态的次数,我们首先使用基于z分数的峰值检测技术(Brakel 2014),并将阶段分为二/三状态。
5.1.1 峰值检测和状态分类
假设是一个时间序列数据。基于z分数的峰值检测方法基于统计色散理论,其中z分数为no。时间序列X的当前值高于或低于该序列的平均值的标准差。根据当前时间的观测值是高于还是低于平均值,可以是正的,也可以是负的。该方法检测时间序列X中的峰值,当该值超出移动平均线的若干标准差时(brake 2014;Hong et al. 2021)。该算法需要设置三个参数:滞后(l),它决定了将使用多少数据点来重新计算移动平均值和标准偏差;阈值(th),即新数据点距离平均值有多少个标准差才能被归类为峰值;以及影响,控制峰值在计算新移动均值和标准差时的影响(Lima et al. 2019)。这种峰值检测技术的方程如下所示:
(5.1)在Eq.(5.1)中,为滤波信号,为z分数,为推断信号,峰值为1,衰减为1,点为0,点位于上阈值和下阈值之间。图3显示了它。分别为滞后参数、影响参数和阈值参数。基于z分数的鲁棒峰值检测伪代码如下所示:

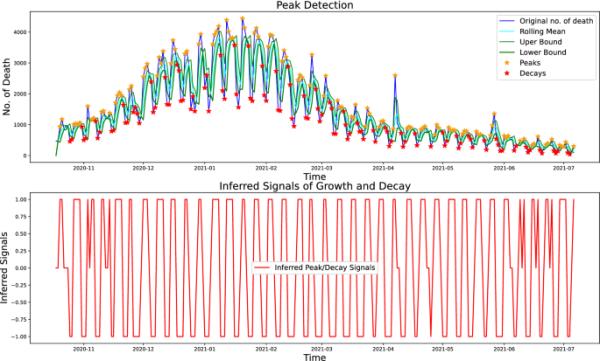
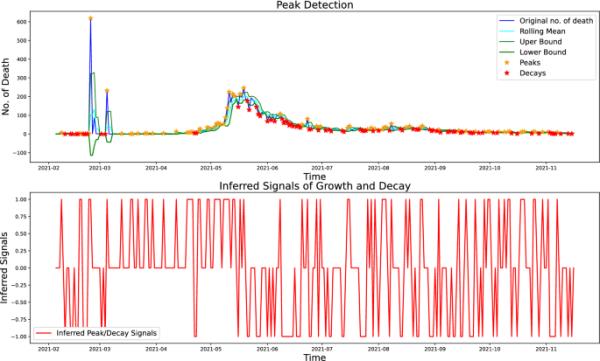
基于Z-score的峰值检测技术在美国新冠肺炎第二阶段死亡人数中的应用
图3显示了大流行第二阶段(2020-10-18至2021-07-06)期间美国死亡人数的峰值检测技术。黄色的星星表示峰值,而红色的星星表示衰变点。第二个图显示了从第5.1节中描述的峰值检测算法推断出的信号。分别以(2,1.5,0.5)作为参数、滞后(l)、阈值(th)和影响的值推导。对于两态二分类模型,我们不考虑位于移动下界和上界之间的点。在双态模型中,这些点要么处于增长状态,要么处于衰减状态之间,这意味着,当某一状态持续时,该状态在时刻t的斜率减小,反之亦然。然而,对于三态三分马尔可夫噪声,我们考虑所有的状态,生长,静止或暂停状态和衰减状态,它们可以以任何顺序出现。
每个数据点的两种状态分类,用于美国第二阶段的Covid
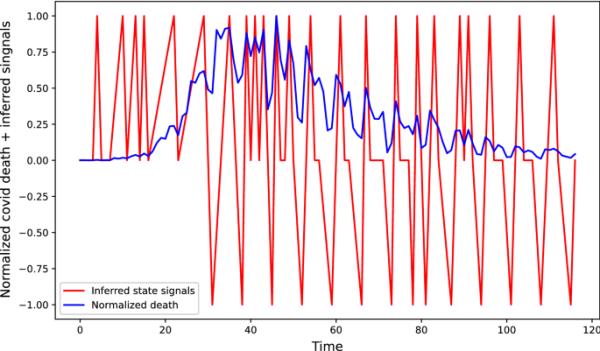
英国新冠肺炎第一阶段每个数据点的三个状态分类
在图4和图5中,推导出的信号随归一化级数no。分别为美国和英国新冠肺炎第二阶段和第一阶段的死亡人数,参数与病例图3相同。通过将每个序列除以该特定序列的max(X),将死亡人数归一化。上升趋势的红线达到1表示其生长状态,下降趋势的线达到0表示其衰变状态,这些线的斜率将分别给出生长参数和衰变参数。然而,在图5中,有三种状态,在0处开始或停止的线为平稳状态,在平稳状态下,参数和简单地为0。当出现暂停状态时,这只会延迟其他两个事件的增长或衰减。用下式计算斜率:
(5.2)方程(5.2)给出了斜率,如果斜率为正,则为增长状态,如果斜率为负,则为衰退状态。在计算了每个状态变化的生长和衰减的斜率之后,我们将得到生长和衰减状态的斜率数组,然后我们取各自数组的平均值,即参数和。
对于给定时间范围内生长和衰减的频率,我们只需存储每个状态变化的离散时间差,从式(5.2)中,我们只需存储k。因此,我们将拥有生长和衰减的时间差k数组。然后我们计算生长和衰减的频率为:
(5.3)现在,因为我们有了我们需要的所有四个参数,我们现在可以通过Eq.(3.4)计算最终的期望值V。对于三分模型,我们计算不同状态之间转换所需的不同频率。例如,从式(3.10)中,对于暂停状态到生长的频率,首先,我们收集从暂停状态到生长的每个状态的离散时间差k,并将其存储在数组中,然后计算as,
(5.4)我们对其他频率也做了类似的处理,我们计算给定状态之间转换的时间离散差的平均值,并计算出Eq.(5.4)中的频率。比方说,我们想要计算暂停状态到衰减状态之间转换的频率,我们会收集离散时间差的数组,然后是,1除以的平均值。一旦我们有和所有的转换频率,,我们计算TMN的期望V如Eq.(3.10)所示。
5.1.2 des数据但又
所使用的数据下载自Dong et al.(2020),该数据依次引用(Mathieu et al. 2021),时间跨度为2020-02-02至2022-06-02。对于与COVID-19死亡相关的数据,使用从Dong等人(2020)下载的csv数据,特别是使用列new_deaths进行时间序列分析和DMN/TMN参数建模。每周对new_deaths列进行分组,以消除数据中不必要的噪声和振荡,因为这会影响模型的参数。我们分析的国家有美国、英国、尼泊尔、澳大利亚和新西兰。这些具体国家是根据数据报告和这些国家为应对这一流行病所采取的政策选出的。不同阶段的时间因国家而异,每个国家每个阶段的确切时间见表1。对于外生变量的时间序列建模,ICU入院和住院被用作特征。这些对应于数据集中的icu_patients和hosp_patients列。
5.1.3 案例研究
在本节中,我们对DMN和TMN参数进行了模拟,并分析了不同国家不同阶段COVID-19的期望值V和长期平均值L。
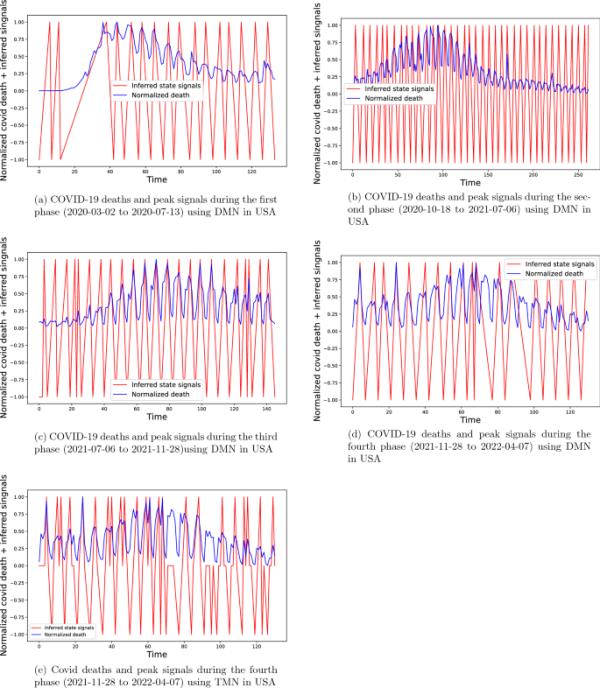
利用DMN和TMN模型对美国新冠病毒在不同阶段的生长、衰减和平稳状态进行分类
在图6d中,滞后参数l取3,图6中其余阶段取2,其他参数相同,阈值参数取1.5,影响参数取0.5。在图6e中,使用TMN模型对三种状态进行分类。而在其他阶段,没有相当大的暂停状态,我们可以看到,美国的新冠肺炎第四阶段有大量的暂停状态。
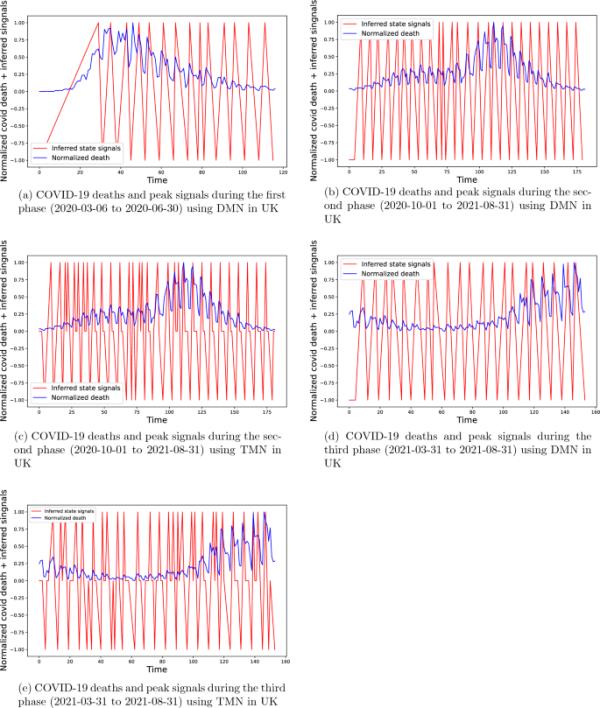
使用DMN模型对英国COVID-19第一、第二阶段的生长、暂停和衰退状态进行分类
在图7中,各相位的滞后参数为3,阈值和影响参数与图6相同。在图8中,滞后参数为2,其他参数保持不变。
对于尼泊尔的COVID-19第二阶段,表1中报告的期望值V非常低,因为大部分时间内,死亡人数保持为0或接近0,这也可以从图9中看到。
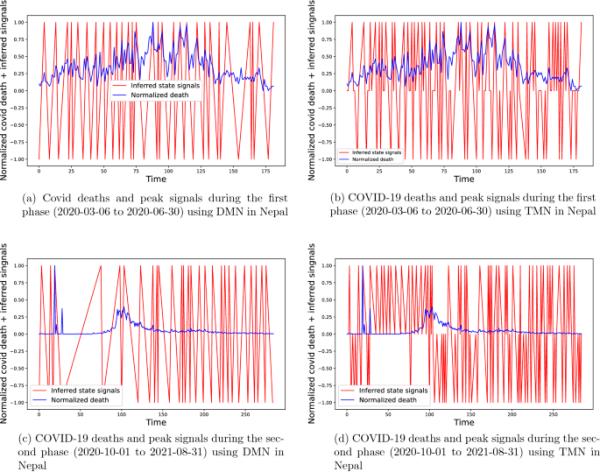
利用DMN和TMN模型对尼泊尔不同阶段COVID-19的生长、暂停和衰减状态进行分类
尼泊尔COVID-19第二阶段的峰值检测和推断信号
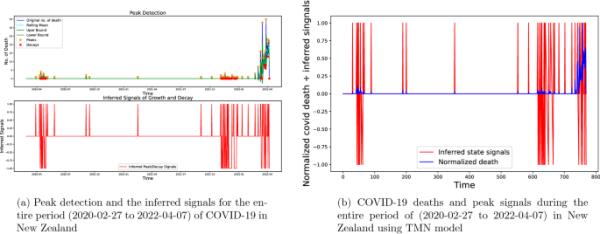
本研究中考虑的新西兰COVID-19整个持续时间内的生长、暂停和衰退状态的分类
澳大利亚新冠肺炎不同阶段生长、暂停和衰减状态的分类
在图10中,我们展示了新西兰COVID-19演变的三个状态,我们可以看到,有很长一段时间的停顿,没有急剧的增长或衰减事件,但由于我们的峰值检测技术是自适应的,它确实根据该时间范围的移动平均线检测状态,因此出现了过渡。在图10中,我们没有显示DMN信号的图,因为DMN模型在这种情况下可能不是完美的选择,因为我们已经看到了普遍的暂停状态。
在表1中,我们分别用和表示DMN和TMN的值,用和表示它们的长期平均值。如果所分析阶段的形势动态保持不变,则两者都显示了Covid-19的长期行为。我们在不同国家的COVID-19的所有阶段都使用DMN和TMN,并评估其潜在动态。对于一些国家,我们还将整个持续时间作为单个阶段进行分析,并对这些参数进行评估。和表示的长期值越小越好。如果V是正的,这意味着在给定的情况下,生长将占主导地位,如果V是负的,这意味着衰减将占主导地位,如果V是0,这意味着会有振荡行为。我们应该注意,这些长期值是针对特定阶段的,这些阶段可能有其自身的社会、战略和环境动态,如果这些动态保持不变,那么我们就可以分析COVID-19的渐近行为(图11)。
在图12中,我们给出了研究期间不同国家DMN和TMN参数的演变曲线图。值得注意的是,由于新冠肺炎死亡人数是标准化的,因此这些国家之间的V值和长期平均值L实际上是可以比较的。DMN和TMN参数也进行了相位和整体分析,我们可以看到,在那些暂停期较大的国家,DMN和TMN的值接近于0,类似于这些参数的平均值。这在新西兰、澳大利亚和尼泊尔的情况下尤为明显,当我们考虑整个COVID-19时期时。我们可以注意到,无论两州模型还是三州模型,美国的平均V和L都更大。同样,我们可以看到,在不考虑暂停状态的情况下,V和L的值更大,但有时,当我们考虑暂停状态时,V的值减少了一半以上。以美国为例,在第一阶段,和较低,和也类似。在第二阶段,这些值增加的幅度不大,而增加的幅度很大(从1.53达到7.57)。在第三阶段,同样是翻倍,但减少,而几乎翻倍。在第四阶段,这些值都急剧增加,除了。这些数值并不能很好地说明COVID-19在美国的渐近行为。英国在第一阶段有一个大的开始,但在第二阶段,第三阶段,它略有下降,在最后两个阶段保持不变。同样,对于所有三个阶段,值都是一个常数0.04。英国的长期值从2.12开始,在第二阶段下降到1.0,在第三阶段略有上升,但三状态模型的长期值似乎几乎是恒定的。这些结果表明,相比之下,英国比美国做得更好。在尼泊尔的情况下,和开始较高,然后在第二阶段迅速下降。对于长期值也类似,并显示出类似的模式。然而,当我们考虑尼泊尔COVID-19的整个持续时间并使用DMN和TMN进行建模时,期望值V和长期值L都处于最低水平,表明尼泊尔将逐渐变得更好。但我们也应该注意到,我们假设数据是正确报告的。澳大利亚的两种模式在第一阶段都有更高的V和L,在第二阶段,它下降了一半以上,这表明,他们在第二阶段比第一阶段做得好,L的低值是一个好兆头。由于新西兰没有相当大的阶段,我们对COVID-19的整个持续时间进行了建模,我们可以看到,期望值V和长期值L都是其他任何国家中最低的。事实上,最好的情况是0。但由于V型病毒仍然存在,我们注意到COVID-19也将渐近地留在新西兰。
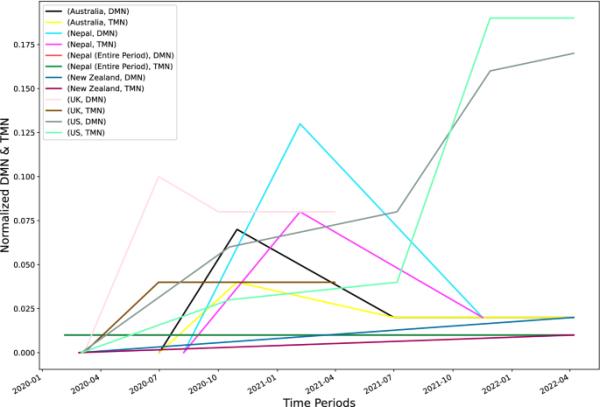
不同国家的DMN和TMN值
5.2 使用时间序列方法进行分析
对于COVID-19动态的短期分析,我们依赖于Mathieu et al. (2021), Dong et al.(2020)提供的数据,时间跨度为2020-02-02至2022-06-02。我们使用基于时间序列的方法进行了许多分析,以评估COVID-19死亡。COVID-19爆发后,一些作品(Tan et al. 2022;ArunKumar et al. 2021;Rguibi et al. 2022;Toutiaee et al. 2021;Konarasinghe 2021;Yadav et al. 2022;Paiva et al. 2021;Carvalho et al. 2021;Wei and Billings 2021;Ayoobi et al. 2021;Luo et al. 2021)对COVID-19感染和死亡建模的研究已经发表,其中大多数(Tan et al. 2022;ArunKumar et al. 2021;Rguibi et al. 2022;Toutiaee et al. 2021;Konarasinghe 2021;Yadav et al. 2022)使用自动回归综合移动平均(ARIMA)模型或季节性ARIMA模型,也称为SARIMA模型或SARIMAX模型。和一些作品(Rguibi et al. 2022;Toutiaee et al. 2021;Konarasinghe 2021;Yadav et al. 2022;Paiva et al. 2021;Wei and Billings 2021;Ayoobi et al. 2021;Luo等人(2021)也将时间序列方法与其他一些技术相结合来预测动态。也有使用深度学习方法完成的工作(Rguibi et al. 2022;Carvalho et al. 2021),有时优于其他方法。但为了简单起见,我们坚持使用数学上易于处理的ARIMA和SARIMA模型,因为我们的目标不是提高预测精度,而是分析和检查使用DMN和TMN评估的短期和长期(渐近)行为之间是否存在任何相关性。
5.2.1 自回归综合移动平均(ARIMA),季节nal ARIMA (SARIMA)和SARIMA带外生变量(SARIMAX)模型
Box和Pierce David(1970)引入的ARIMA模型用于在时间序列中各值之间存在相关性时建立预测模型。ARIMA模型由三个部分组成,首先是自回归,即将时间序列与前一个时间序列进行回归。换句话说,这告诉我们,时间序列的当前t值依赖于一些滞后的时间序列值。第二个分量,集成部分,表示时间序列的差异,而第三个分量移动平均包含了观测值与移动平均模型的残差之间的依赖关系,应用于滞后观测(Rguibi et al. 2022)。
这三个分量(AR, Integrated和MA)也被视为p, d, q,其中p表示no。d为差分阶数(例如,1为一阶差分,2为二阶差分,依此类推),q为移动平均的窗口大小(Rguibi et al. 2022;Toutiaee et al. 2021;Seabold and Perktold 2010)。根据Rguibi et al.(2022),我们可以将ARIMA模型表述为:
(5.5)式中为该序列在t周期的预测值,基于t周期前的观测值。参数为模型常数,为AR系数,为滞后k时的MA系数。项为周期内的预测误差。
虽然我们使用时间序列差分、自相关和部分自相关函数来评估三个参数p、d、q,但使用AutoArima (Smith et al. 2017)函数来确定建模参数,这些参数最小化了Akaike信息准则(AIC)。当p和q为0时,ARIMA模型变为纯回归模型Seabold and Perktold(2010)。
SARIMA(季节性自回归综合移动平均)模型是我们在5.2.1节中描述的ARIMA模型的扩展。在该模型中,ARIMA(p, d, q)伴随着额外的季节项,以解释对应于单个季节周期的m个时间步长的时间序列的季节性。其中P、D、Q分别为季节AR项、季节差异项和季节移动平均项的顺序(ArunKumar et al. 2021)。SARIMA模型可定义如下(Toutiaee et al. 2021;Seabold and Perktold 2010),
(5.6)其中是要预测的变量,就单变量结构模型而言,也可以表示为(Seabold and Perktold 2010),其中是测量误差或白噪声过程。是p阶正则AR多项式,是q阶正则MA多项式,是p阶季节性AR多项式,是q阶季节性MA多项式。是差分阶,是季节差分算子。
当SARIMA模型需要对一个或多个外生变量进行建模时,可以将之前的模型进行扩展,以考虑这些外生变量,并将这种模型定义为SARIMAX。在SARIMAX中,式(5.6)可以扩展为ArunKumar et al. (2021);
(5.7)其中n个外生变量在t时刻定义,并带有各自的系数。
5.2.2 实验
我们使用ARIMA、SARIMA和SARIMAX模型对美国全国发生的COVID-19死亡进行了大量实验。这里,死亡数表示美国每周新增死亡人数。首先,我们根据COVID-19的多个阶段对整体数据进行划分,并使用不同顺序的ARIMA/SARIMA/SARIMAX模型进行建模。对于SARIMAX,使用了ICU入院和住院等外生变量,这些特征是经过实验选择的。我们将每个阶段的数据大致取为一个训练样本,其余用于测试,除了第一阶段的数据作为初始训练和滚动测试。我们使用AIC作为模型选择标准,并使用平均绝对百分比误差(MAPE)和对称平均绝对百分比误差(SMAPE)来评估模型。这两个分数都是越小越好。MAPE和sMAPE误差使用以下表达式计算,实际值和预测值:
(5.8) (5.9)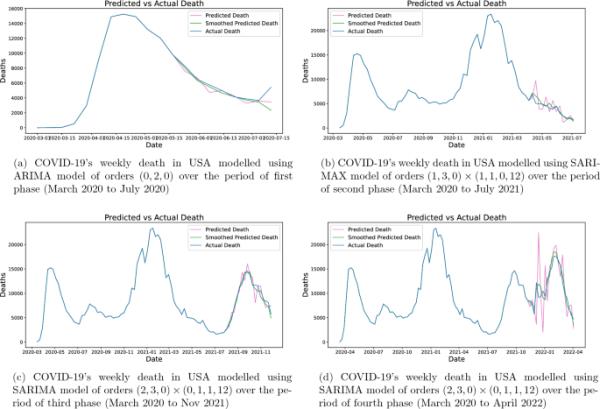
美国新冠肺炎每周死亡人数的时间序列分析
在图13中,我们使用滚动预测技术来预测第t周的新冠肺炎每周死亡人数。在滚动预测技术中,我们使用t点之前的所有数据点来训练模型,并使用它来预测后续时间步的死亡人数。我们重复同样的过程,直到我们得到数据的最后,所以预测是提前一周的预测。为了减少模型的振荡预测,我们对预测的窗口大小为3取移动平均,这似乎改善了整体MAPE和SMAPE误差。对于第一阶段,我们简单地使用ARIMA模型,因为在这种情况下AR和MA分量都是0,所以该模型是一个简单的回归模型。从第二阶段开始,我们有更多的每周数据,因此我们也使用季节性成分。对于SARIMAX模型,如前所述,使用ICU入院和住院特征总体上改善了预测。但在第三和第四阶段,SARIMA(没有任何外部输入)的表现似乎略好一些,但当我们考虑整体数据时,情况并非如此,我们将在后面看到。我们可以在图13d中看到,如何使用移动平均平滑预测有助于减少模型的误差。在上述实验中,即使我们在每个阶段添加更多的数据,预测也只能在该特定阶段的范围内进行。
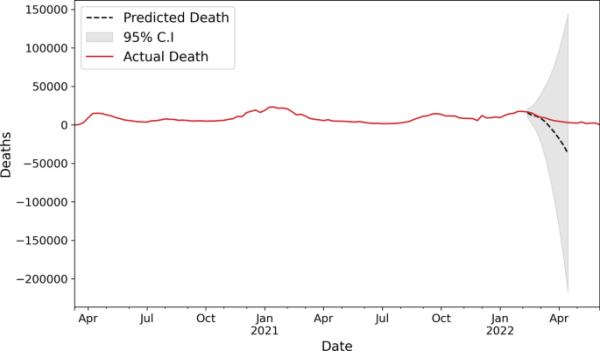
COVID-19每周死亡人数,使用SARIMAX建模,提前5周预测和置信区间
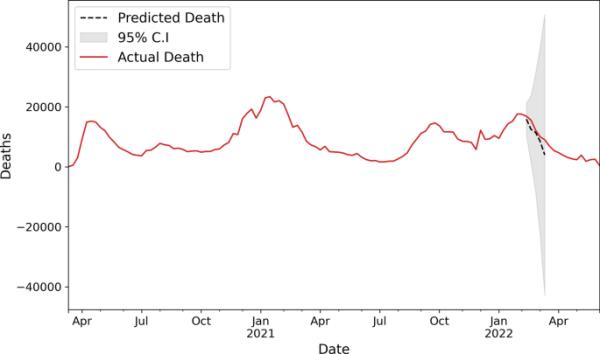
在图14中,我们使用SARIMAX对每周新增死亡人数进行建模,我们提前5周进行预测,与图13中的提前一周预测不同,我们仍然获得了良好的MAPE和sMAPE误差。我们使用2020-03-15 - 2022-02-13的数据对模型进行训练,并对接下来的5周,即2022-02-21 - 2022-03-27进行预测测试。
但是,如果我们继续增加预测的周数,那么这种方法就会受到影响,无法再做出好的预测。从图15中可以看出,当我们进行10周的提前预测时,SARIMAX模型失去了预测能力,出现了发散,需要定期输入才能正确预测未来可能的情况。因此,这些方法只能用于短期预测。在表2中,我们列出了ARIMA、SARIMA和SARIMAX模型对COVID-19不同阶段以及总体数据的拟合结果。在分阶段分析中,我们坚持提前一周滚动预测,在整体模型中,我们做了提前5周和10周的预测。
COVID-19每周死亡人数,使用SARIMAX建模,提前10周预测和置信区间
5.3 短期和长期分析的比较
为了比较短期时间序列分析与长期DMN和TMN模型,我们比较了时间序列模型预测死亡的变化率(速度)与DMN和TMN模型的参数,增长()和衰减()。我们的想法是看看时间序列模型中的平均速度与DMN和TMN模型中的增长率和衰减率之间是否存在任何关系。这是给出的平均变化率,
(5.10)我们的假设是,平均而言,它应该更接近于参数,就它们的增长和衰减而言。但这是我们的假设,表3中的结果并没有显示出它们之间的太多或任何相关性。
表3中时间序列列表示预测COVID-19死亡时生长事件的平均变化率或斜率,同样时间序列表示时间序列模型预测COVID-19死亡时衰变事件的平均变化率。我们将它们与两态(DMN)和三态(TMN)模型的结果进行了比较。总的来说,我们可以看到它们似乎不相关,在第一阶段,衰变速率很接近,但在其他阶段,这些值都不相似。因此,我们可以得出结论,就比较而言,我们从时间序列模型得到的死亡值的平均变化率与我们从DMN和TMN得到的平均生长和衰减参数之间没有相似之处。
6 讨论与结果
本文采用两态随机进化模型(DMN)和三态随机进化模型(TMN)对5个不同国家的COVID-19动态进行了分析。我们分析了阶段和整体的动态。我们展示了两种状态模型如何完美地符合不同国家由COVID-19引起的振荡死亡。我们还展示了三状态模型是如何适应长期运行的,因为我们评估了阶段内和阶段过渡期间的暂停状态。通过评估DMN和TMN的平均参数,我们可以看到COVID-19在这些国家将保持渐近状态。然而,如果我们评估整个时间段,这些参数的渐近值在新西兰、澳大利亚和尼泊尔等国家接近于0。在美国,DMN和TMN模型的期望值略高于其他国家,同样,特别是第二和第四阶段的长期平均值也较高,这表明在这些条件下,COVID-19的增长将占主导地位。在英国和澳大利亚,这些价值似乎正在从第一阶段开始的地方下降。新西兰是唯一一个DMN长期平均值为0的国家。所有这些结果表明,COVID-19在这些国家将保持渐近状态。因为,至少据我们所知,使用DMN/TMN准确分析COVID-19渐近行为的研究尚不存在,我们没有其他研究可以直接比较我们的结果,但这项工作确实开辟了进一步使用这些模型来分析自然界和社会中存在的类似现象的可能性。
我们还使用时间序列模型分析了COVID-19的短期动态。我们使用了ARIMA、SARIMA和SARIMAX模型。由于我们使用了一周滚动预测方法,因此死亡预测的MAPE评分略好于ArunKumar等人(2021),以及使用两周滚动预测的Toutiaee等人(2021)评估的sMAPE评分。我们评估了提前一周滚动预测的表现更好,同时我们还评估了这些模型在预测COVID-19的长期行为时的影响。我们还评估了使用住院和ICU患者作为输入特征可以改善整体预测,这与Toutiaee等人(2021)的研究结果一致。由于这项工作的目的是展示评估COVID-19长期和短期动态的可能标准,因此我们没有对时间序列模型本身进行综合实验,而是只在美国一个国家进行实验。我们还将DMN和TMN的长期平均增长率和平均衰减率与短期时间序列分析得到的短期增长率和衰减率进行了比较。在我们的数值结果中,我们发现它们之间没有相关性。但由于我们既没有建立DMN/TMN与自回归时间序列模型之间的数学模型,也没有明确地试图建立它们之间的关系,我们展示了两种方法之间的最小比较,并为未来的研究开辟了可能性,在那里我们可以研究长期和短期模型之间的关系。
6.1 限制
随机进化模型为预测新冠肺炎动态的长期行为提供了有效的规则,但也存在局限性。与任何其他建模方法一样,核心限制在于COVID-19建模的固有哲学和因果关系。在这种方法中,我们关注的是环境动力学,而不是病毒的内部动力学。在数学技术方面,有必要研究开发时间序列技术与随机进化方法相结合的数学方法。由于本文的范围,如果可以建立短期和长期分析之间的某种关系,我们就无法进行充分的实验。
7 总结
本文对COVID-19死亡病例的短期和长期行为进行了研究。对于短期分析,使用ARIMA, SARIMA和SARIMAX来预测不同国家的死亡人数。我们使用随机进化方法(二分法和三分法马尔科夫噪声)来模拟COVID-19死亡病例的长期行为。因此,我们为治疗、疫苗接种和其他预防性保健做法(如保持社会距离)的有效性建立了一个标准,因为随机进化模型可以模拟大流行病在特定情况下的长期行为。时间序列模型可以用来评估短期行为。在这方面,我们使用了美国、英国、新西兰、澳大利亚和尼泊尔的真实数据进行对比和预测。由此我们可以看到COVID-19动态在这些国家的渐近行为,结果表明COVID-19将在所有这些国家保持渐近状态。我们还比较了DMN和TMN的长期增长和衰减参数与时间序列的短期增长和衰减,没有发现相关性。所提供的技术具有一般用途,可用于类似框架中的决策制定。
下载原文档:https://link.springer.com/content/pdf/10.1007/s00477-023-02455-8.pdf